I decided to play with some numbers over the weekend, inspired by the unbelievably bizarre events in the US senate during the Kavanaugh confirmation hearings.
A core principle of free and fair elections, a cornerstone of democracy, is one vote per person and that all votes are counted equally, right? Not so in the US.
So, to put some numbers on it, I dug up the population by state and did some simple calculations.
The representation in the House of Representatives is pretty closely matched to the population, there’s always going to be some differences since it’s based on the previous census, but it’s close enough. That part is OK.
The US Senate is another story though. Each state has 2 senators for a total of 100 for the 50 states. It may have been a good idea back in the late 1700s, but it’s absurdly skewed today. I live in California and we have 2 senators representing the roughly 40 million people living here. That’s 12.1% of the US population. Now, if you try to match that population by adding up the states from the smallest and up until you reach 40 million – you get 22 states with 44 senators (out of a 100). That’s 44% of the US senators. So on one hand you have the 12.1% of the population in California represented by 2% of the senators. The other 12.1% (adding up smaller states) have 44% of the Senate.
Note, this is just a numbers game, strictly by population numbers by state. I haven’t weighted it by party, but if you look at the map below, your see that this favors one party much more than the other.
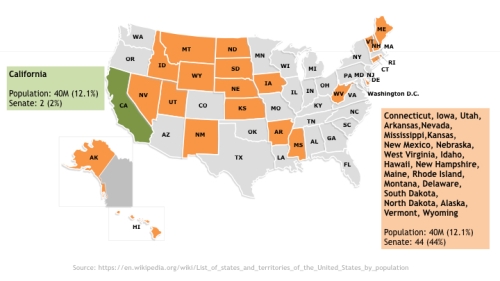
Now, I could make a very similar argument for the underrepresentation of Texas, Florida and New York (together with California, they are the 4 largest states by population). You would need to add up 34 state populations to match those 4 largest states, i.e. 68 senators vs the 8 that represent California, Texas, Florida and New York
There are arguments, for checks and balances and to not go strictly by population numbers to make the voices of the smaller states heard. I can understand that, but the numbers are so skewed today that the current system just doesn’t make sense.
Maybe it’s time to limit the impact of the senate? Much like European parliaments have adjusted to the times and limited (or abolished) the upper houses of their parliaments. The UK is a good example of this, where their upper house, the House of Lords, can scrutinize bills, and force reconsiderations, but rarely is able to stop a bill.
To make matters worse, the election that is supposed to chose the president for all of USA is also skewed towards the smaller states. Not as extreme as the Senate, but enough so that we got a White House Squatter that took possession with 2.8 million fewer votes than the woman that in any normal democracy would have been the winner. If the president is supposed to represent the people of the USA, then who that is should be decided based on the total number of votes nationwide, without an electoral college.
Just saying…







